Benchmarking Gob vs JSON, XML & YAML
The article describes nuances and details of benchmarking the speed and memory in terms of encoding & decoding data in Gob comparing to JSON, XML & YAML.
Recently I was doing some coding and I accidentally came across Gob while googling needed stuff. It took me by and I was really into this, that’s why you’re reading this article with my experiment described!

Gob is a serialization technique specific to Go only. Gob is designed to work with Golang-based data types. For instance, JSON (and others too) supports struct data type only, if we’re talking in terms of Go. While Gob is not restricted so and does support all data types but functions and channels. It means you’re able to encode simple data types like int, string etc. Gob encodes data into a binary format and decodes into a corresponding data type. Another advantage of Gob is worth to say is that it doesn’t encode empty values, the empty value is to be decoded to the default one based on the type. This approach allows to increase the performance.
TL;DR
For those of you, who doesn’t really like reading a looong articles, here’s my Github repo with everything described here.
Another TL;DR
Here is the full analysis of mine about all the outcomes I’ve got — Analysis.md
Instead of Intro
I was aware about Gob, but haven’t tried. So I decided to give a try and compare how it behaves against the most popular options like JSON, XML and YAML.
The solution designed consists of the following steps:
- create several structs with different size and complexity
- implement encoding and decoding functions for each format
- implement tests for benchmarking each item as a single struct, a slice of structs, a slice of pointers to the struct
- implement a separate complex map type for a face-to-face benchmarking of Gob vs JSON
- run the benchmarking itself and analyze results
First, let’s create all the structs. I named them as Tiny, Medium, Big, Huge and ComplexAndHuge — the last one is intended to run Gob vs JSON only (since XML doesn’t support map parsing out-of-the-box in Go).
And yeah, naming the stuff always been the weakest part of mine ;))
Designing structs
So, let’s start with Tiny, it will look like below:
I’ve already added tags for each data format. And I’ll not be posting code snippets of functions generating the structs with filled fields. It’s kinda primitive stuff, so I’d omit it here. Alternatively, feel free to spot it here.
Let’s proceed! The others will look like these:

That’s it! Now we’re moving to the next phase which is encoding & decoding functions.
Encode & decode functions
As it’s said at the beginning, Gob is supported by Go natively, meaning it has a built-in package to work with — “encoding/gob”:
II decided to keep it as simple as possible and thus not handling errors properly. That’s not a good approach in the real code.
The same should be done for JSON, XML & YAML via using corresponding built-in pkg — “encoding/json”, “encoding/xml”, “gopkg.in/yaml.v3”.
Do not forget to implement functions with filling up the structs with dummy data!
Let’s move to the next phase, which is nothing but implementing the actual benchmarking tests! One of the most interesting parts to me!
Designing tests
As we’ll be using a built-in “testing” pkg (obviously), we need to implement a struct (another one!) to run the test conveniently. It should contain a name (printing for clarity), a target struct (one of the created above), and an encoding function.
Then we’ll populate a slice of that testing struct with the data needed for benchmarking and iterate over it by invoking each item using b.Run() function.
So eventually it’ll look like:
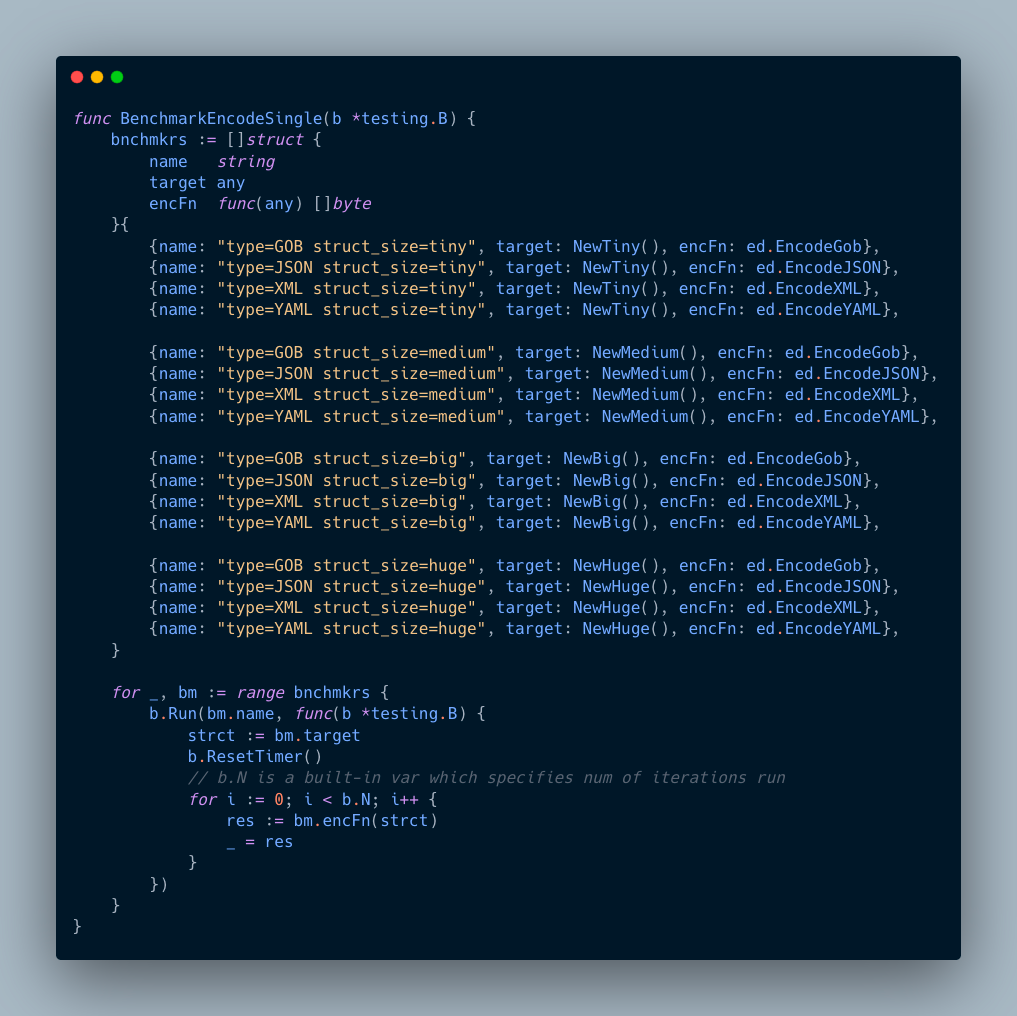
If you’re unclear with the inner loop going thru b.N var: it’s a built-in variable which represents amount of times being run for each benchmark. AFAIK, it seeds a random value (actually, not random, but suitable for Go itself). We’ll use a separate flag to set the value for it and run exact times.
Let’s do a test for decoding then. It’ll be slightly different as it needs a decoding function to be defined and invoked lately:

As you can see on the snippet above, we defined a list of benchmark structs which contains a name, a func to get a struct instance with data filled, encoding and decoding functions for corresponding format.
I also wanna point out the b.ResetTimer() lines you may notice in the snippet — it’s needed to reset the time as we need only one operation (decoding or encoding) to be calculated, and not everything in the entire function.
Other tests could be found here.
Benchmarks running
Now we’re all set to run, obtain and analyze the results!
Run the benchmarks by the following terminal cmd:
go test -bench=. -benchmem -benchtime=10x > result.csvWait for a while (it may take a few mins, as the struct sets are huge indeed) and have a look at the generated csv file with the results.
FYI, I did separate Make commands for more comfortable running — here.
Obtaining results
It should be smth like the ones below, but more comprehensive.
Decoding a single struct based on size:
goos: darwin
goarch: arm64
pkg: github.com/RSheremeta/gob-serialization
BenchmarkDecodeSingle/type=GOB_struct_size=tiny-10 10 12662 ns/op 6760 B/op 179 allocs/op
BenchmarkDecodeSingle/type=JSON_struct_size=tiny-10 10 1354 ns/op 248 B/op 6 allocs/op
BenchmarkDecodeSingle/type=XML_struct_size=tiny-10 10 3317 ns/op 1481 B/op 33 allocs/op
BenchmarkDecodeSingle/type=YAML_struct_size=tiny-10 10 6912 ns/op 7280 B/op 52 allocs/op
BenchmarkDecodeSingle/type=GOB_struct_size=medium-10 10 21038 ns/op 8603 B/op 235 allocs/op
BenchmarkDecodeSingle/type=JSON_struct_size=medium-10 10 5550 ns/op 457 B/op 14 allocs/op
BenchmarkDecodeSingle/type=XML_struct_size=medium-10 10 12917 ns/op 3609 B/op 92 allocs/op
BenchmarkDecodeSingle/type=YAML_struct_size=medium-10 10 17762 ns/op 10850 B/op 126 allocs/op
BenchmarkDecodeSingle/type=GOB_struct_size=big-10 10 26250 ns/op 11545 B/op 324 allocs/op
BenchmarkDecodeSingle/type=JSON_struct_size=big-10 10 10129 ns/op 1081 B/op 32 allocs/op
BenchmarkDecodeSingle/type=XML_struct_size=big-10 10 45050 ns/op 10377 B/op 280 allocs/op
BenchmarkDecodeSingle/type=YAML_struct_size=huge-10 10 57829 ns/op 23200 B/op 386 allocs/op
BenchmarkDecodeSingle/type=GOB_struct_size=huge-10 10 1645925 ns/op 1274254 B/op 22501 allocs/op
BenchmarkDecodeSingle/type=JSON_struct_size=huge-10 10 12986658 ns/op 3220468 B/op 37218 allocs/op
BenchmarkDecodeSingle/type=XML_struct_size=huge-10 10 69240829 ns/op 22169344 B/op 564327 allocs/op
BenchmarkDecodeSingle/type=YAML_struct_size=huge#01-10 10 88956475 ns/op 37407429 B/op 745485 allocs/op
PASS
ok github.com/RSheremeta/gob-serialization 2.324sEncoding a slice of structs based on their size:
goos: darwin
goarch: arm64
pkg: github.com/RSheremeta/gob-serialization
BenchmarkEncodeSlice/type=GOB_struct_size=tiny-10 10 7862 ns/op 1392 B/op 22 allocs/op
BenchmarkEncodeSlice/type=JSON_struct_size=tiny-10 10 3721 ns/op 562 B/op 1 allocs/op
BenchmarkEncodeSlice/type=XML_struct_size=tiny-10 10 10217 ns/op 5072 B/op 9 allocs/op
BenchmarkEncodeSlice/type=YAML_struct_size=tiny-10 10 23217 ns/op 37584 B/op 129 allocs/op
BenchmarkEncodeSlice/type=GOB_struct_size=medium-10 10 9962 ns/op 4600 B/op 62 allocs/op
BenchmarkEncodeSlice/type=JSON_struct_size=medium-10 10 14142 ns/op 4674 B/op 21 allocs/op
BenchmarkEncodeSlice/type=XML_struct_size=medium-10 10 56579 ns/op 18710 B/op 72 allocs/op
BenchmarkEncodeSlice/type=YAML_struct_size=medium-10 10 142608 ns/op 340952 B/op 877 allocs/op
BenchmarkEncodeSlice/type=GOB_struct_size=big-10 10 67688 ns/op 69401 B/op 571 allocs/op
BenchmarkEncodeSlice/type=JSON_struct_size=big-10 10 195138 ns/op 79204 B/op 451 allocs/op
BenchmarkEncodeSlice/type=XML_struct_size=big-10 10 883075 ns/op 298070 B/op 1116 allocs/op
BenchmarkEncodeSlice/type=YAML_struct_size=big-10 10 2440958 ns/op 6520168 B/op 13745 allocs/op
BenchmarkEncodeSlice/type=GOB_struct_size=huge-10 10 75574500 ns/op 109713207 B/op 690111 allocs/op
BenchmarkEncodeSlice/type=JSON_struct_size=huge-10 10 267247896 ns/op 127877377 B/op 611006 allocs/op
BenchmarkEncodeSlice/type=XML_struct_size=huge-10 10 1184146242 ns/op 316476485 B/op 1498028 allocs/op
BenchmarkEncodeSlice/type=YAML_struct_size=huge-10 10 4233214871 ns/op 12425343834 B/op 18662808 allocs/op
PASS
ok github.com/RSheremeta/gob-serialization 64.692sDecoding a map of structs (Gob vs JSON only):
goos: darwin
goarch: arm64
pkg: github.com/RSheremeta/gob-serialization
BenchmarkDecodePtrSliceComplexMap/type=GOB_struct_size=huge_complex_map-10 10 646447171 ns/op 630836108 B/op 11072058 allocs/op
BenchmarkDecodePtrSliceComplexMap/type=JSON_struct_size=huge_complex_map-10 10 6356559012 ns/op 1610172119 B/op 18605410 allocs/op
PASS
ok github.com/RSheremeta/gob-serialization 85.338sAs you can see, each benchmark contains the value “10” — that’s the amount of times run. That’s the b.N value mentioned earlier and we set it in the terminal command above.
All results can be found on my Github.
Analyzing the results
Based on the outcome I got after multiple runs, the analysis turned out to be a pretty comprehensive stuff, so I put it in a separate doc called Analysis.md in my repo and will analyze the results only briefly here.
So, my brief analysis is the following:
- It’s not worth to use Gob for a small- or medium-sized data (either single or sliced), JSON is the best here.
- Gob is way faster than anything compared here in terms of encoding/decoding huge structs as well as complex types.
- XML is surprisingly fast in decoding a slice of any size of the structs.
- Gob is better than JSON in speed of encoding & decoding a complex map type of any kinds — a single type, a slice, a slice of pointers to the type.
- YAML took mostly the last place with the worst results shown.
Instead of a summary
Data formats are a critical aspect of programming, as they determine how efficiently data is stored and processed. In this article, we benchmarked several popular data formats, to determine which one performs the best in terms of speed and memory usage. However, the optimal choice of data format ultimately depends on the specific needs of your project and the trade-offs you’re willing to make.
Thank you note
Thank you for the reading the article. I do hope you’ll find my experiment useful for yourself!
Feedbacks and subscriptions are appreciated!
Also, I’d invite you to check out another articles from myself: